海量数据——这就是我们现在正在处理的问题。除了这一主要挑战外,各种来源的复杂性也随之而来。在这样的环境中,SQL仍然是英雄,是我们不可或缺的工具,用于从这片数据海洋中导航和提取有价值的见解。
在 SQL 提供的许多强大功能中,窗口函数特别值得注意。这些函数支持跨表行集进行复杂的计算,使它们对于高级数据分析和改变我们与数据交互的方式至关重要。
在今天的文章中,我们将剖析和理解 SQL 中窗口函数的概念。我们将探讨何时使用窗口函数,以及如何在我们的 SQL 查询中有效地实现它们。在本指南结束时,您将对窗口函数的强大功能和灵活性有更深入的理解,并且您将配备实际示例来提高您的数据分析技能。
— — 准备好了吗—— —?走吧 🚀 — — —— —
这个窗口功能是怎么回事?
每个数据爱好者,无论他们的经验水平如何,都可能听说过甚至使用过窗口函数。这些强大的工具在每门 SQL 课程中无处不在,在任何与数据打交道的人的日常生活中都是必不可少的。
让我们在 Google 上做一个快速搜索......过了一会儿,也许是电视上的广告,我们发现窗口功能是:
一个函数,它使用一行或多行的值来返回每行的值 - 基于维基百科
或
一种强大的工具,通过提供一种计算跨行子集(称为“窗口”)的值的方法,使数据分析师和开发人员能够对数据集执行完整的分析计算,该方法基于 Analytics Vidhya
有人说过语法吗?
是的,没错。这个超级强大的工具带有一些技巧,例如特定的语法。
— 不要害怕,到本文结束时,一切都会被驯服
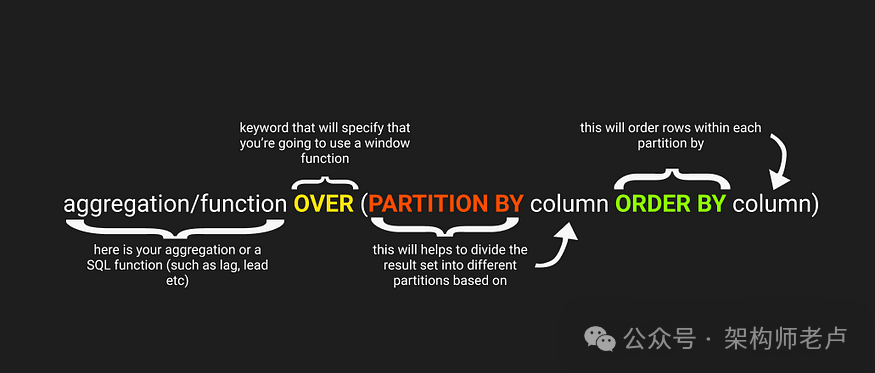
正如我们在上图中看到的,窗口函数的语法可以分为四个部分:
聚合/函数:这是通过放置聚合(如 、)或特定窗口函数(如 、、、或 )来启动操作的地方。还有一些,但这些是最常用的(或者至少是我使用最多的😁)AVGSUMLAG()LEAD()ROW_NUMBER()RANK()DENSE_RANK()
OVER:此关键字专门用于向 IDE “宣布”您将使用窗口函数。这就像在说,“我要在这里做点什么,你最好为复杂的事情做好准备。
PARTITION BY:此子句将结果划分为分区或窗口,在此之上我们将应用我们在开始时建立的聚合或函数。写完这部分之后,你还需要开发你所基于的分区字段。这不与排名函数一起使用。
订购 BY:在某些情况下这可能是可选的,但了解它的作用是值得的。这用于对每个分区内的行进行排序,并且在使用排名函数(如 、 和 )时显示了它的有用性。RANK()DENSE_RANK()ROW_NUMBER()
许多窗口功能以实现您的目标
在上一节中,我们讨论了窗口函数语法。我们提到了一些函数,这些函数永远不会独立于窗口函数语法工作。
有些称为排名函数,因为它们为分区中的每一行返回一个排名值;其他是时间序列窗口函数。
排名功能:
等级() — 为结果集的分区中的每一行分配一个等级,其中值相等的行将获得相同的等级。
DENSE_RANK() —类似于 **RANK(),**但具有连续的秩值。相等的值获得相同的等级;下一个排名值是下一个连续的整数。
NTILE() — 它将结果集划分为相等的组,并为每行分配一个数字以指示它属于哪个组。
ROW_NUMBER() — 为结果集的分区内的行分配一个唯一的顺序整数,每个分区中的第一行从 1 开始。
时间序列函数:
永恒的问题:为什么......
我们为什么要这样做?我们为什么要学习这一点?我们为什么要使用它??
这些是我们对很多事情提出的常见问题,SQL 中的窗口函数也不例外。为了了解窗口函数可以为您节省时间和精力的情况,让我们来探讨一下:
为什么以及何时我们应该使用窗口函数?
让我们从WHEN开始。我们什么时候使用窗口函数?好吧,每当我们需要时:
不要把 “为什么”留在外面。 当情况需要时,我们为什么要使用窗口函数?
因为窗口功能:
维护行级别详细信息 — 允许我们在不折叠数据的情况下执行计算,使您能够在保持原始数据完好无损的情况下跨多行执行计算。
简化复杂查询— 该工具帮助我们简化最复杂的查询,使它们更易于阅读、编写,最重要的是,易于维护。
提高性能 — 通常可以带来更好的性能,尤其是对于大型数据集,因为它们由 SQL 引擎优化。
启用高级分析 — 允许我们运行高级分析操作,例如运行总计、移动平均线等。
对数据进行分区以进行详细分析 — 根据特定条件对数据进行分区,从而在组内进行详细分析,而无需聚合整个数据集。
支持时间序列和更改检测 — 为访问上一行或下一行值提供内置支持,这对于时间序列数据和更改检测非常有用。
真实世界的用例
作为一名在银行业工作的数据工程师,我收到了一个请求,要求识别合同“阶段”发生变化的记录,并捕获此变化的日期。
说起来容易做起来难,对吧?不完全是,因为窗口函数帮助我完成了请求并快速交付了结果。
假设我们有两个表:
source.data_records
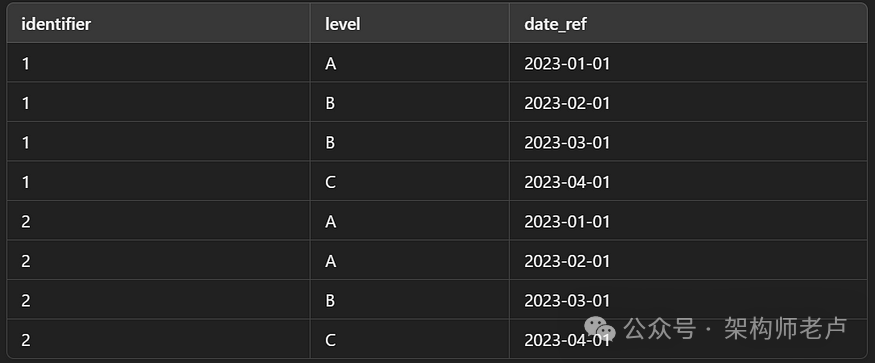
以及temp.data_records:
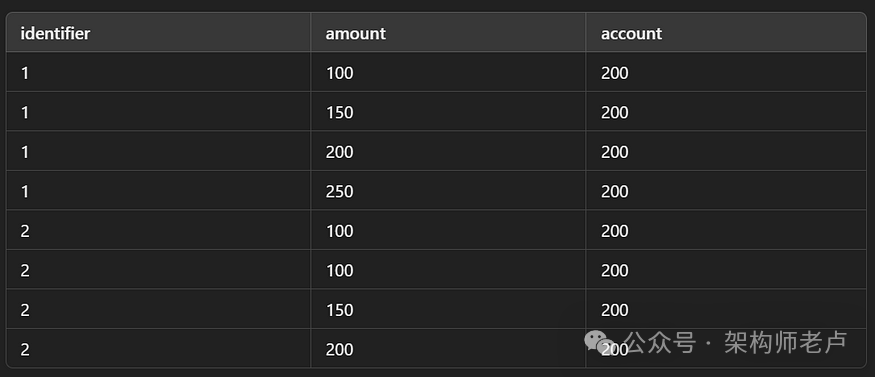
我们需要创建一个表,在其中保存以下信息:
标识符
标识符的当前级别
当前阶段的基准日期
标识符的上一级
上一个参考日期
标识符更改其级别的日期
该表是根据以下代码创建的:
create table tmp_change_level_date as
(
select distinct * from (
select
fct.identifier, fct.level, fct.date_ref,
lag(fct.level) over (partition by fct.identifier order by fct.date_ref) as previous_level,
lag(fct.date_ref) over (partition by fct.identifier order by fct.date_ref) as previous_date,
case
when lag(fct.level) over (partition by fct.identifier order by fct.date_ref) is not null then fct.date_ref
else NULL
end as change_level_date,
dense_rank() over (partition by fct.identifier order by fct.date_ref desc) as ranks
from source.data_records fct join temp.data_records TFCT
on fct.identifier = TFCT.identifier
where TFCT.amount <> 0 and TFCT.account in (select account_code from accounts_list)
) x
where ranks = 1
and level <> previous_level
and previous_date <> change_level_date
)
commit;
现在,让我们深入了解一下解释:
首先,我创建了主语句,在该语句中我获取了标识符(贷款标识符)、水平和date_ref等信息(这 2 个是贷款的实际水平和当前阶段的参考日期):SELECT
select
fct.identifier, fct.level, fct.date_ref,
lag(fct.level) over (partition by fct.identifier order by fct.date_ref) as previous_level,
lag(fct.date_ref) over (partition by fct.identifier order by fct.date_ref) as previous_date,
case
when lag(fct.level) over (partition by fct.identifier order by fct.date_ref) is not null then fct.date_ref
else NULL
end as change_level_date,
dense_rank() over (partition by fct.identifier order by fct.date_ref desc) as ranks
from source.data_records fct join temp.data_records TFCT
on fct.identifier = TFCT.identifier
where TFCT.amount <> 0 and TFCT.account in (select account_code from accounts_list)
) x
之后,我使用函数来获取贷款的前一级和每笔贷款的上一个参考日期。使用 ,我根据标识符 将数据集划分为小分区,并按date_ref对每个分区内的记录进行排序.
lag(fct.level) over (partition by fct.identifier order by fct.date_ref) as previous_level,
lag(fct.date_ref) over (partition by fct.identifier order by fct.date_ref) as previous_date
并使用函数为分区中的每条记录分配一个等级:DENSE_RANK()
dense_rank() over (partition by fct.identifier order by fct.date_ref desc) as ranks
此代码将返回以下结果:
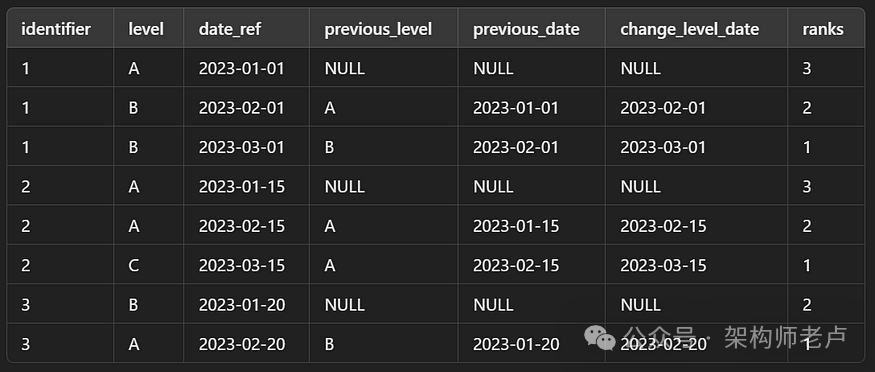
更进一步,我们编写另一条语句,以便能够对上一个结果(上表)应用一些过滤器:SELECT
select distinct * from (
---- the previous select as a subquery ----
) x
where ranks = 1
and level <> previous_level
and previous_date <> change_level_date
并且仅获取每个标识符的最新记录(ranks=1 对应于说明前面的最新记录),即当前级别与上一级别(级别 <> previous_level)不同的记录,并确保更改日期有效且与上一个参考日期不同。根据这些过滤器,我们将结果插入到新的表tmp_change_level_date中(我们使用著名的 CREATE TABLE table_name AS 语法创建的表):

从这些结果中,我们看到:
结论
SQL 窗口函数简化了复杂的数据分析并增强了性能。本文介绍了它们的基础知识、语法、常见用法(如排名和时间序列分析)以及一个真实示例。掌握这些功能有助于简化 SQL 查询,从而实现高效且有洞察力的数据工作。
该文章在 2024/7/24 23:33:41 编辑过






 400 186 1886
400 186 1886


